What's AGI?

This post gives a brief definition of AGI.
AdvancedRobotics(WeChat Public): What’s AGI?
Brief Definition of AGI
目前,工业界最火的就是人工智能领域,即AI(Artificial Intelligence)。那什么是AI呢?Computer science defines AI research as the study of “intelligent agents”: any device that perceives its environment and takes actions that maximize its chance of successfully achieving its goals. A more elaborate definition characterizes AI as “a system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation.”(Definition from Wikipedia) 翻译过来就是:任何能够感知环境并采取行动最大化其成功实现目标之机会的设备即为人工智能。这里面包含了两个关键因素:(1) 能够感受并了解环境的特征,即感知;(2) 能够基于目标最大化成功概率而采取行动,即决策。其实,人工智能又常被成为机器智能,其相对于人类的自然智能来讲还是相差很大的距离。若要达到人类的智慧水平,就要具备以下能力:
- 存在不确定性因素时进行推理,使用策略,解决问题,制定决策的能力;
- 知识表示的能力,包括常识性知识的表示能力;
- 规划能力;
- 学习能力;
- 使用自然语言进行交流沟通的能力;
- 将上述能力整合起来实现既定目标的能力。
能够达到上述水平的人工智能,即称之为人工通用智能AGI(Artificial General Intelligence)。做一个假设,随着科学技术不断发展,计算机比世界上最聪明,最有天赋的人还聪明,那么,由此产生的人工智能系统可以称为人工超级智能ASI(Artificial Super Intelligence)。当然,这个目标离我们还比较遥远,暂且不讨论。
Method to AGI
AGI作为人工智能领域一个中长期目标,其发展还是遵循一条主线,就如上面描述,其首先要解决的两个问题就是感知和决策,再谈学习和泛化。AGI的发展脉络可以简单地用下图来说明,即遵循的步骤是:1. 深度学习解决分类,检测,识别问题,即目标特征到语义属性的离散映射关系,即感知。有了感知,机器就可以熟悉认识其周围的环境;2. 深度强化学习解决序列决策问题,即环境状态到智能体行为动作的连续耦合映射关系,即决策。有了决策,机器智能体就可以基于目标最大化与环境进行交互;3. 深度元学习解决快速学习泛化问题,即智能体行为动作间的逻辑映射关系,即学习推理。有了学习推理,机器智能体就能够构建自己的知识体系,从而形成经验以适应环境进而生存。
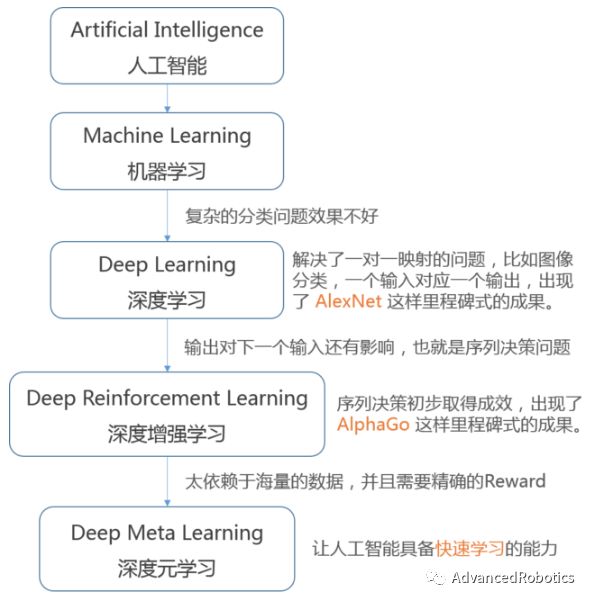 Definition of AGI - 1
Definition of AGI - 1
对于深度学习和深度强化学习,相信大家都已经比较熟悉。简单来讲:深度学习,即利用深度神经网络特有的感知能力对目标的特征进行提取与识别,其卷积核本质上等同于滤波器,从而实现对物体的分类和检测等;深度强化学习,即利用状态转移概率可知的马尔可夫过程对最大化奖励的行为策略求解或者对状态转移概率不可知的值函数最大化的行为/策略进行估计,其本质上是属于动态规划问题,从而解决智能体连续决策问题。这里涉及到深度二字,是因为强化学习中也涉及到很多深度网络的迁移使用。那么深度元学习呢?
 Definition of AGI - 2
Definition of AGI - 2
元学习(Meta Learning-learning to learn)最初由Donald B. Maudsley (1979) 描述为“学习者意识到并且越来越多地控制他们已经内化地感知,探究,学习和成长习惯的过程”。Maudsely将他的理论的概念基础设定为在假设,结构,变革过程和促进的标题下合成。阐述了五个原则以促进元学习。学习者必须:
- 有一个理论,无论多么原始;
- 在安全的支持性社会和物质环境中工作;
- 发现其规则和假设;
- 重新与环境中的显示信息联系起来;
- 通过改变其规则/假设来重组自己。
John Biggs(1985)后来使用元学习的概念来描述“意识到并控制自己的学习”的状态。可以将元学习定义为对学习本身现象的认识和理解,而不是学科知识。这个定义隐含着学习者对学习环境的感知,包括了解学科的期望是什么,更简单地说,是对特定学习任务的要求。在这种背景下,元学习取决于学习学者的学习观念,认识论信念,学习过程和学术技能,在此总结为一种学习方法。具有高水平元学习意识的学生能够评估她/他的学习方法的有效性,并根据学习任务的要求对其进行管理。相反,元学习意识低的学生将无法反思她/他的学习方法或学习任务集的性质。因此,当学习变得更加困难和苛刻时,他/她将无法成功适应。
 Definition of AGI - 3
Definition of AGI - 3
AGI Future Summary
根据前人的经验和总结,就人脑工作特点和人工智能的发展来看,目前比较可能实现AGI的几个可行方向如下:
- Meta Learning: 元学习,即learning to learn。其不仅仅是提供一种方式来学会学习(learning to learn->optimizer/optimizer),从而学得更好更快,更本质的是提供了一种提取不同信息相互联系的方法。既然仍然是监督学习,meta learning可以学到无监督学习,meta learning不再是简单的mapping,而实可以内在的做无监督学习,这种架构将有可能自动实现hierarchy,实现逻辑性。
- Hierarchy Model: 可以针对神经网络在网络结构层面进行改进,神经网络的分层不仅仅是在时间尺度上,按照逻辑我们人类做的任何决策都是一种hierarchy,从本质结构上,人脑和神经网络有很大的相似之处。
- Modular Neural Networks: 可以在网络结构层面进行改进,神经网络模块化一定是一种趋势,因为我们未来将会看到一个神经网络能够同时处理视觉、语音、控制等等各种输入输出,没有模块化是办不到的,这类似于人类大脑不同区域的不同功能,但是里面有很多信息可以共用和迁移。
- 广义RL: 带反馈的广义强化学习。广义RL的形式反映了人类如何获取信息并转化为知识和技能的过程,最后形成一种经验常识被固化保留下来,从而能够作为一种高级语义信息被传播和重复利用,这是高级智慧的体现。广义RL为机器智能体学习提供了一套通用的框架。
- Transfer Learning: 随着人工智能的大规模部署和应用,在实际场景中网络训练的时耗以及网络模块的迁移重用将会是应用过程中的重要部分,而且工作量繁重。所以,必须让网络模块具备自适应迁移的功能,能够在近似的场景中进行快速部署和应用,这就意味着需要让网络稍加修改和微调训练就能够使用,即迁移学习。
所谓的通用人工智能就是要让人工智能能够只用同一套算法学习掌握各种各样的任务,而不是单一任务从头训练。因此,通用人工智能必须具备快速学习能力,快速学习能够让每个人拥有的人工智能系统都不一样。不难看出,快速学习是实现通用人工智能AGI的必由之路,而元学习(Meta Learning)又是实现快速学习的重要方法之一。
To be continued ……